L’affermazione che “un valore booleano dovrebbe contenere solo due valori, Vero o Falso“, è generalmente accettata. Tuttavia, talvolta si trascura il fatto che il valore potrebbe essere completamente assente.
Nei database, questa assenza è comunemente memorizzata come NULL.
In questo articolo, esamineremo come individuare tali valori nulli, come gestirli correttamente e offrirò alcuni suggerimenti basati sulla mia esperienza personale per la gestione di NULL in PostgreSQL.
È importante notare che non solo i booleani possono avere valori NULL, ma anche tutte le colonne dove non è definita una restrizione (constraint) NOT NULL possono contenerli.
INDICE
Gestione dei valori nulli in PostgreSQL
Partiamo dalle basi: abbiamo un database PostgreSQL e creeremo una tabella chiamata “utenti” con la seguente struttura:
CREATE TABLE utenti (
id_utente SERIAL,
nomeutente TEXT PRIMARY KEY,
nome TEXT,
cognome TEXT,
eta INT
);

Aggiungiamo ora alcune righe di dati alla tabella degli utenti appena creata.
INSERT INTO utenti (nomeutente, nome, cognome, eta) VALUES
('gigi', 'Giuseppe', 'Garibaldi', 35),
('anga','Anita', 'Garibaldi', 25),
('gileo','Giacomo', 'Leopardi', 45),
('jrambo','John','Rambo',38);

Quando viene eseguita una query, la tabella viene visualizzata con tutte le colonne complete.

Inserimento di valori NULL
Ora proviamo ad inserire alcuni valori NULL nelle colonne nome, cognome ed età.
INSERT INTO utenti (nomeutente,nome,cognome,eta)
VALUES ('test',NULL, NULL, NULL);
Questo avviene perché non abbiamo definito alcuna restrizione (constraint).
Se eseguiamo nuovamente la query sui dati inseriti, noteremo che le colonne in cui abbiamo inserito NULL non mostrano nessun valore.

Possiamo semplificare ulteriormente l’inserimento specificando solo le colonne a cui vogliamo assegnare un valore, ottenendo lo stesso risultato.
INSERT INTO utenti (nomeutente) VALUES ('test_02'),('test_03');
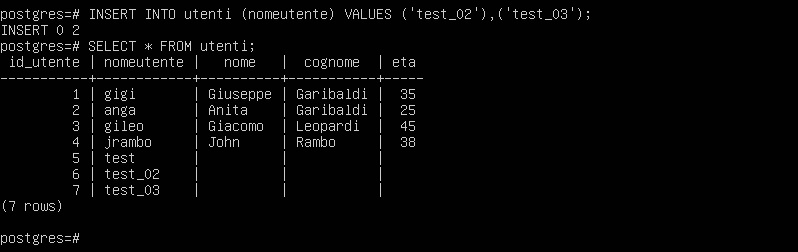
Gestione dei valori nulli - Inserimento dei valori NULL
Il primo passo per evitare la presenza di valori NULL in una tabella è impedirne l’inserimento.
Successivamente, esamineremo diverse situazioni su come evitare l’inserimento di NULL sia nelle colonne nuove che in quelle già esistenti.
Inserire NULL nella chiave primaria (Primary Key)
È consentito inserire un NULL nella chiave primaria della tabella?
In teoria, ciò potrebbe essere permesso poiché non c’è una restrizione (constraint) NOT NULL esplicita sulla colonna.
Proviamo a farlo:
INSERT INTO utenti (nomeutente) VALUES (NULL);
La query correttamente scritta dovrebbe funzionare, ma invece restituisce un messaggio di errore:

Siamo giunti alla nostra prima conclusione:
Creare una nuova colonna con la restrizione (constraint) NOT NULL
Se proviamo ad aggiungere una nuova colonna alla tabella del nostro esempio, denominata “punteggio”, e specificare che non deve contenere valori NULL, useremo il seguente comando:
ALTER TABLE utenti ADD COLUMN punteggio integer NOT NULL;
Il comando restituirà un errore poiché i dati inseriti precedentemente non hanno nessun valore associato alla colonna “punteggio”.

Per prevenire questo problema, dovremmo creare la nuova colonna specificando un valore predefinito (DEFAULT).
Il comando sarebbe il seguente:
ALTER TABLE utenti ADD COLUMN punteggio integer NOT NULL DEFAULT 0;
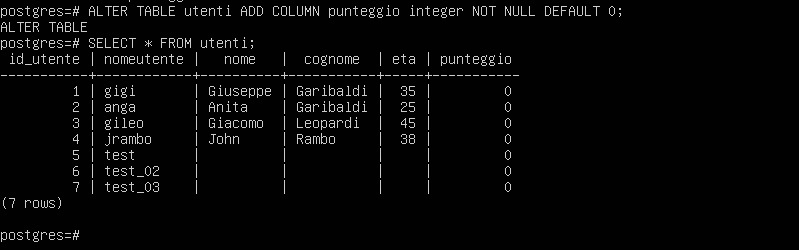
Come si può notare dalla schermata precedente, la tabella è stata modificata e ora tutte le righe esistenti hanno un valore ‘zero’ nella colonna punteggio.
Se proviamo a inserire una nuova riga senza specificare la colonna punteggio, osserveremo che il valore predefinito impostato viene assegnato con successo.
INSERT INTO utenti (nomeutente) VALUES ('simone10');

Proviamo a inserire un valore nullo nella colonna punteggio e vediamo cosa succede.
INSERT INTO utenti (nomeutente,punteggio) VALUES ('teresa22',NULL);

Abbiamo ricevuto l’ERRORE: il valore nullo nella colonna “punteggio” della relazione “utenti” viola la restrizione di non nullità, il che indica che il nostro INSERT sta violando la restrizione NOT NULL.
Inoltre, in base a quanto abbiamo osservato, possiamo giungere a una terza conclusione:
Aggiungere una restrizione NOT NULL a una colonna esistente
Se tentiamo di modificare una colonna esistente (ad esempio, “nome”) per aggiungere la restrizione NOT NULL, otteniamo il seguente errore: “ERRORE: la colonna “nome” della relazione “utenti” contiene valori nulli”.
ALTER TABLE utenti ALTER COLUMN nome SET NOT NULL;

Quindi, è anche necessario modificare i valori nulli attuali (e eventualmente impostare un valore predefinito).
ALTER TABLE utenti
ALTER COLUMN nome TYPE TEXT USING (COALESCE(nome, 'Mario')),
ALTER COLUMN nome SET DEFAULT 'Mario',
ALTER COLUMN nome SET NOT NULL
;

Con il comando precedente abbiamo:
- Modificato il tipo di dati della colonna, ridefinendola come TEXT, e applicato la funzione COALESCE(nome, ‘Mario’), che sostituisce i valori nulli nella colonna “nome” con “Mario”.
- Impostato il valore predefinito per la colonna “nome” come “Mario”. Questo passaggio non è strettamente necessario.
- Applicato la restrizione NOT NULL, senza ricevere un messaggio di errore poiché non ci sono valori nulli nella colonna.
I risultati corrispondono a quanto atteso: non ci sono valori nulli nella colonna “nome”, poiché sono stati sostituiti da ‘Mario’.

Se vogliamo rimuovere la restrizione NOT NULL da una colonna, possiamo farlo utilizzando il seguente comando:
ALTER TABLE utenti
ALTER COLUMN nome DROP NOT NULL
;
È sufficiente utilizzare "DEFAULT"?
Cosa accade se omettiamo la restrizione NOT NULL e impostiamo semplicemente un valore predefinito?
Proviamo a creare una nuova colonna chiamata “primo_login” e vediamo come appare la nostra tabella.
ALTER TABLE utenti
ADD COLUMN primo_login DATE DEFAULT CURRENT_DATE;

Come possiamo notare dall’esempio, la colonna “primo_login” è stata popolata con la data odierna in tutte le righe della tabella.
Se proviamo ad aggiungere una nuova riga senza specificare un valore per “primo_login”, verrà assegnata automaticamente la data odierna.
INSERT INTO utenti (nomeutente) VALUES ('tizio01');
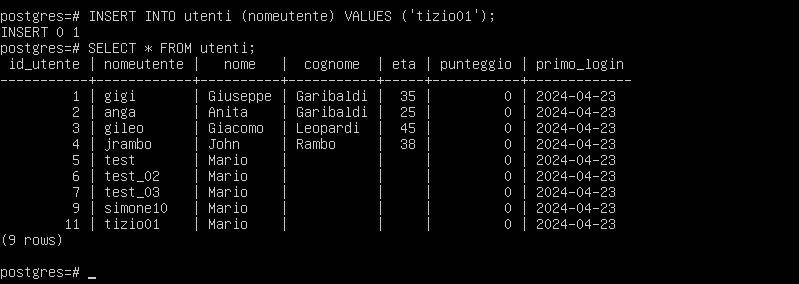
Come dimostrato, la nuova riga viene inserita correttamente con un valore non nullo nella colonna “primo_login”.
Quindi, è davvero necessario specificare la restrizione NOT NULL?
La risposta è SI, poiché potrebbero essere inseriti valori nulli specificandoli esplicitamente nell’istruzione INSERT, come si dimostra di seguito.
INSERT INTO utenti (nomeutente, primo_login)
VALUES ('tizio02',NULL);

Come si può osservare nella schermata precedente, è stato possibile inserire una nuova riga con un valore NULL per la colonna “primo_login”.
Gestione di NULL - Interrogazione dei valori NULL
Nella sezione precedente abbiamo esaminato come evitare di memorizzare valori nulli nei nostri sistemi.
Ma, come gestire i valori nulli esistenti in una colonna?
In questo caso, possiamo utilizzare alcune funzioni SQL per individuare quei valori e modificarli secondo necessità.
Rilevare i valori nulli con la clausola IS NULL (isNull)
La clausola IS NULL (anche scritta come ISNULL) ci consente di manipolare le righe che potrebbero contenere valori nulli.
Ad esempio:
SELECT * FROM utenti WHERE cognome ISNULL;

Come si può osservare, è stata mostrata la lista di righe che contengono valori nulli nella colonna “cognome”.
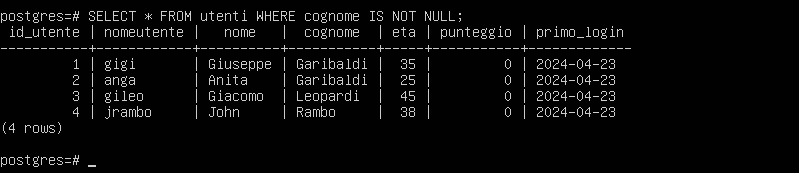
Una lista con valori opposti potrebbe essere recuperata applicando la clausola IS NOT NULL:
SELECT * FROM utenti WHERE cognome IS NOT NULL;
Cosa accade se tentiamo di utilizzare il confronto di uguaglianza (=)?
SELECT * FROM utenti WHERE cognome = NULL;

La query precedente non restituisce alcuna riga perché il valore NULL indica l’assenza di un valore e non è uguale a nessun altro valore (NULL=NULL è Falso).
Inoltre, se applichiamo l’operatore di disuguaglianza (<>) con NULL, otteniamo anche NESSUNA riga, poiché il valore NULL indica l’assenza di un valore e quindi non è né uguale né diverso da altri valori.
SELECT * FROM utenti WHERE cognome <> NULL;
Assegnare un valore predefinito a NULL utilizzando la funzione COALESCE
Nell’esempio precedente, abbiamo visto come individuare i valori nulli.
Ma cosa succede se dobbiamo includerli in una dichiarazione SELECT insieme ad altri valori?
Possiamo aggiungere una condizione OR nel seguente modo:
SELECT * FROM utenti
WHERE cognome = 'Garibaldi' OR cognome IS NULL ;
Possiamo anche applicare una trasformazione per sostituire i valori nulli con un valore con cui possiamo confrontarli.
SELECT * FROM utenti
COALESCE(cognome,'Caio') in ('Caio', 'Garibaldi');
I due esempi precedenti restituiscono lo stesso risultato.

Scegliendo la seconda alternativa, è cruciale verificare che ‘Caio’ (l’etichetta assegnata ai valori nulli) non sia presente nella colonna, o che sia un valore che desideriamo includere nella nostra selezione.
Operazioni matematiche con NULLs
Un caso simile si verifica quando dobbiamo effettuare calcoli su una colonna che ammette valori nulli.
Per esempio, consideriamo la colonna “eta”: cosa accade se vogliamo calcolare l’età media?
Esaminiamo i dati:
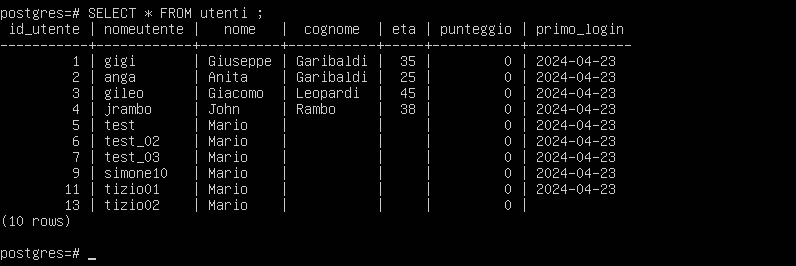
Possiamo calcolare l’età media con il seguente comando:
SELECT AVG(eta) FROM utenti ;

Questo produce un risultato di 35,75, che rappresenta la media delle 4 età NON NULL.
Allo stesso modo, se consideriamo la colonna “primo_login” con il comando:
SELECT COUNT(primo_login) FROM utenti ;

Il risultato è 9, che rappresenta una riga per ogni utente con un valore per “primo_login” diverso da NULL.
Cosa accade se tentiamo di calcolare il punteggio medio?
Per farlo, aggiorniamo innanzitutto la tabella assegnando a ‘simone10’ un punteggio di 45 punti.
UPDATE utenti SET punteggio = 45 WHERE nomeutente = 'simone10' ;
Procediamo a calcolare il punteggio medio.
SELECT AVG(punteggio) FROM utenti ;

Il risultato è 4,5, che rappresenta la media matematica tra i 45 punti di ‘simone10’ e gli zeri degli altri, dato che precedentemente abbiamo impostato zero come valore predefinito.
Tuttavia, la correttezza di questo risultato dipende dall’obiettivo che ci siamo prefissati.
Se volevamo calcolare la media dei punteggi solo degli utenti attivi, questo calcolo potrebbe risultare ingannevole.
JOINS con colonne NULL
Considerando ciò che abbiamo appreso in precedenza sulla distinzione di NULL rispetto ad altri valori, è fondamentale prestare maggiore attenzione quando si gestiscono colonne nulle durante l’esecuzione di JOIN.
Creeremo un’altra tabella chiamata “appuntamenti” e inseriremo alcuni dati.
Per scopi accademici in questo caso, il design di questa tabella ci obbliga a effettuare un JOIN con la tabella “utenti” sulla colonna “cognome”, che accetta valori NULL.
CREATE TABLE appuntamenti (id_appuntamento SERIAL, cognome TEXT, ora TIMESTAMP);
INSERT INTO appuntamenti (cognome, ora) VALUES
('Garibaldi', CURRENT_TIMESTAMP - INTERVAL '1 day'),
('Leopardi', CURRENT_TIMESTAMP - INTERVAL '1 day'*2),
('Rambo', CURRENT_TIMESTAMP - INTERVAL '1 day'*2),
('Rambo', CURRENT_TIMESTAMP),
(NULL, CURRENT_TIMESTAMP),
(NULL, CURRENT_TIMESTAMP - INTERVAL '1 day'*2),
(NULL, CURRENT_TIMESTAMP - INTERVAL '1 day'*2),
(NULL, CURRENT_TIMESTAMP - INTERVAL '1 day'*1),
(NULL, CURRENT_TIMESTAMP);

Se desideriamo contare gli utenti che hanno un appuntamento in ciascun giorno, potremmo scrivere la seguente query:
SELECT EXTRACT(DAY FROM ora), COUNT(distinct nomeutente)
FROM appuntamenti
JOIN utenti ON appuntamenti.cognome = utenti.cognome
GROUP BY EXTRACT(DAY FROM ora);
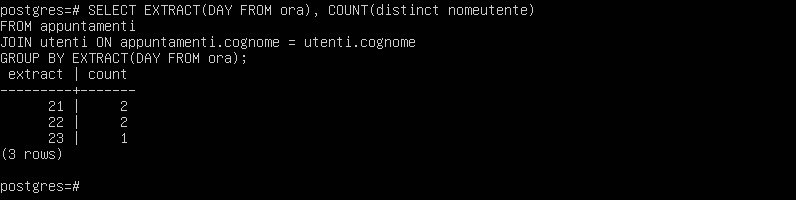
Tuttavia, il risultato mostra solo 5 appuntamenti.
Perché accade questo? Ancora una volta, ciò è dovuto ai valori NULL nella condizione di JOIN.
Questo problema di bassa qualità dei dati in entrambe le parti del JOIN ci impedisce di ottenere un numero utile.
Come potremmo risolverlo? La soluzione risiede nella modifica della struttura della tabella appuntamenti per utilizzare il nome dell’utente anziché il cognome, e anche nel definire una chiave esterna (FOREIGN KEY) adeguata verso la tabella degli utenti.
Se cerchiamo una soluzione semplice, potremmo applicare COALESCE su entrambi i lati della JOIN:
SELECT EXTRACT(DAY FROM ora), COUNT(distinct nomeutente)
FROM appuntamenti
JOIN utenti ON COALESCE(appuntamenti.cognome, 'SenzaCognome') = COALESCE(utenti.cognome, 'SenzaCognome')
GROUP BY EXTRACT(DAY FROM ora);
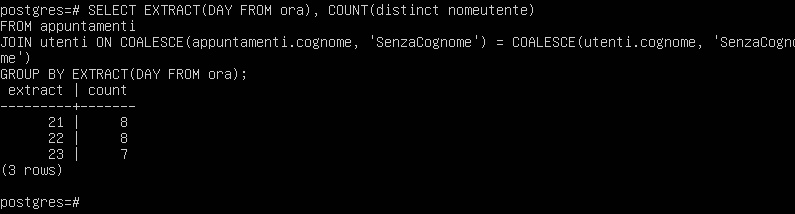
Il risultato mostra un aumento nel conteggio delle riunioni.
Tuttavia, questa non è ancora la risposta corretta, poiché osserviamo che vengono aggiunte 18 riunioni, mentre originariamente ne sono state mostrate solo 5 nella tabella degli appuntamenti.
Perché succede questo? È perché ora abbiamo convertito tutti i valori NULL in “SenzaCognome” su entrambi i lati della JOIN.
Poiché avevamo 5 riunioni senza cognome e 6 utenti senza cognome, stiamo generando una unione cartesiana di tutti i cognomi vuoti con gli appuntamenti vuoti.
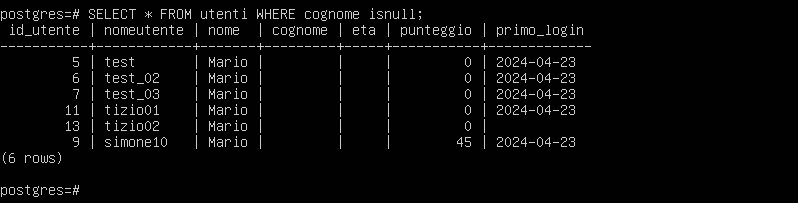
Avevamo identificato i seguenti utenti senza cognome:
Inoltre gli appuntamenti senza cognome

Ogni appuntamento è stato associato a ogni utente, generando un eccesso di appuntamenti.
Una soluzione più adeguata potrebbe essere attribuire tutti gli appuntamenti con valore NULL a un unico utente fittizio chiamato NoUtente.
SELECT EXTRACT(DAY FROM horario), COUNT(distinct COALESCE(nombreusuario,'NoUsuario'))
FROM reuniones
LEFT OUTER JOIN usuarios ON reuniones.apellidos = usuarios.apellidos
GROUP BY EXTRACT(DAY FROM horario);

Tuttavia, affrontare i problemi di qualità dei dati direttamente durante l’esecuzione della query raramente si dimostra una strategia efficace.
Conclusione Finale
La gestione dei valori nulli nei database è cruciale per mantenere l’integrità e la precisione dei dati.
Abbiamo esplorato come i valori nulli possano influenzare le operazioni di query e come affrontare queste eventualità attraverso strategie come l’uso di COALESCE, il design appropriato delle tabelle e le restrizioni.
È importante riconoscere che risolvere i problemi di qualità dei dati al momento della query può essere rischioso, ed è preferibile implementare soluzioni strutturali fin dal design iniziale del database.
In questo modo, possiamo garantire l’affidabilità e la coerenza dei dati nel tempo.