


La afirmación «un valor booleano debería contener solo dos valores, Verdadero o Falso», es generalmente aceptada. Sin embargo, a veces se pasa por alto el hecho de que el valor podría estar ausente por completo.
En las bases de datos, esta ausencia se suele almacenar como NULL.
En este artículo, mostraremos cómo identificar estos valores nulos, cómo utilizarlos correctamente y proporcionaré algunos consejos basados en mi experiencia personal para el manejo de NULLs en PostgreSQL.
Es importante tener en cuenta que no solo los booleanos pueden contener valores NULL, sino que también todas las columnas donde no se define una restricción (constraint) NOT NULL pueden tenerlos.
INDICE

Manejo de NULLs en PostgreSQL
Vamos a empezar desde lo más básico: tenemos una base de datos PostgreSQL y una tabla llamada «usuarios», que crearemos con la siguiente estructura:
CREATE TABLE usuarios (
id_usuario SERIAL,
nombreusuario TEXT PRIMARY KEY,
nombres TEXT,
apellidos TEXT,
edad INT
);

Ingresemos algunas lineas de datos en la tabla usuarios apenas creada.
INSERT INTO usuarios (nombreusuario, nombres, apellidos, edad) VALUES
('bfea', 'Betty', 'La Fea', 25),
('amendoza','Armando', 'Mendoza', 35),
('mavale','Marcela', 'Valencia', 45),
('jrambo','John','Rambo',38);

Al realizar una consulta de datos (query), se muestra la tabla con todas las columnas completas.

Ingreso de valores NULLs
Ahora, intentemos insertar algunos valores NULL en las columnas nombres, apellidos y edad:
INSERT INTO usuarios (nombreusuario,nombres,apellidos,edad)
VALUES ('prueba',NULL, NULL, NULL);
Esto funciona porque no tenemos ninguna restricción (constraint) definida. Si volvemos a consultar los datos ingresados, veremos que las columnas en las que hemos introducido NULL no muestran ningún valor.
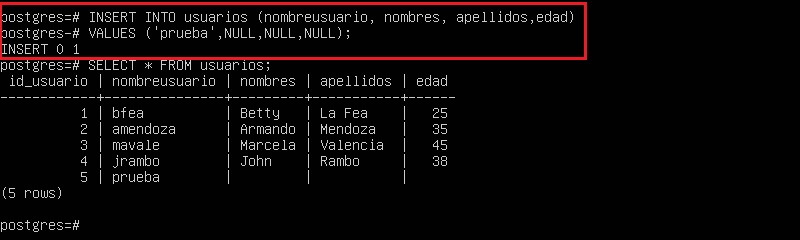
Incluso podemos simplificar la inserción indicando solo las columnas a las que queremos asignar un valor, obteniendo el mismo resultado.
INSERT INTO usuarios (nombreusuario) VALUES ('prueba_02'),('prueba_03');

Manejo de NULLs - Ingresando los valores NULLs
El primer paso para prevenir la presencia de valores NULLs en una tabla es prohibir su inserción.
A continuación, analizamos algunas situaciones sobre cómo evitar la inserción de NULLs en columnas nuevas y en las ya existentes.
Insertar NULLs en la clave primaria (Primary Key).
¿Es posible insertar un NULL en la clave primaria de la tabla?
En teoría, esto podría permitirse ya que no hay una restricción (constraint) NOT NULL explícita en la columna.
Hagamos la prueba:
INSERT INTO usuarios (nombreusuario) VALUES (NULL);
El comando correctamente escrito debería funcionar, sin embargo, da como resultado un mensaje de error:

Hemos llegado a nuestra primera conclusión:
Crear una nueva columna con la restricción (constraint) NOT NULL.
Si intentamos agregar una nueva columna a la tabla de nuestro ejemplo, misma que llamaremos puntaje, y especificamos que no debe contener valores NULL usando el siguiente comando:
ALTER TABLE usuarios ADD COLUMN puntaje integer NOT NULL;
El comando devolverá un error porque los datos previamente insertados no tienen ningún valor asociado para la columna «puntaje».

Para prevenir este problema, deberíamos crear la nueva columna especificando un valor predeterminado (DEFAULT).
El comando sería el siguiente:
ALTER TABLE usuarios ADD COLUMN puntaje integer NOT NULL DEFAULT 0;
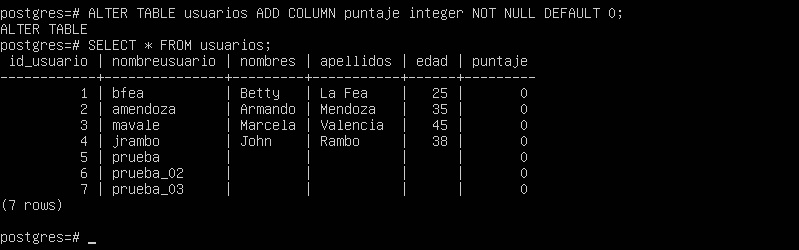
Como se puede observar en la captura de pantalla anterior, la tabla ha sido modificada y ahora todas las filas existentes tienen un valor igual a ‘zero’ en la columna puntaje.
Si intentamos insertar una nueva fila sin especificar la columna puntaje notaremos que si se logra ingresar y viene asignado el valor predeterminado establecido.
INSERT INTO usuarios (nombreusuario) VALUES ('simon10');
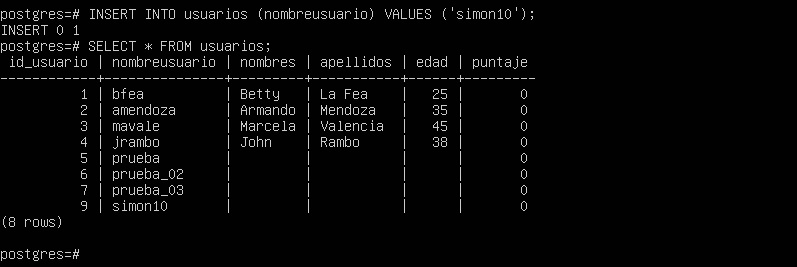
Veamos qué sucede si intentamos ingresar un valor nulo en la columna puntaje.
Hagamos la prueba para averiguarlo.
INSERT INTO usuarios (nombreusuario,puntaje) VALUES ('teresa22',NULL);

Recibimos, ERROR: el valor nulo en la columna «puntaje» de la relación «usuarios» viola la restricción de no nulidad, lo que indica que nuestro INSERT está incumpliendo la restricción NOT NULL.
Además, según lo que hemos constatado, podemos llegar a una tercera conclusión:
Agregar una restricción NOT NULL a una columna existente
Si intentamos cambiar una columna existente (por ejemplo, nombres) para agregar la restricción NOT NULL, obtenemos: ERROR: la columna «nombres» de la relación «usuarios» contiene valores nulos.
ALTER TABLE usuarios ALTER COLUMN nombres SET NOT NULL;

Por lo tanto, también es necesario modificar los valores nulos actuales (y posiblemente establecer un valor predeterminado).
ALTER TABLE usuarios
ALTER COLUMN nombres TYPE TEXT USING (COALESCE(nombres, 'Juan')),
ALTER COLUMN nombres SET DEFAULT 'Juan',
ALTER COLUMN nombres SET NOT NULL
;

Con el comando anterior hemos:
- Modificamos el tipo de datos de la columna, volviéndola a definir como TEXT, y aplicamos la función COALESCE(nombre, ‘Juan’), que sustituye los valores nulos en el campo «nombres» con «Juan».
- Establecimos el valor predeterminado para la columna «nombres» como «Juan». Esto no es estrictamente necesario.
- Aplicamos la restricción NOT NULL, y esta vez sin obtener un mensaje de error ya que no quedan valores nulos en la columna.
Los resultados coinciden con lo esperado: no hay valores nulos en la columna nombres, ya que han sido reemplazados por ‘Juan’.

Si deseamos eliminar la restricción NOT NULL de una columna, podemos lograrlo con el siguiente comando:
ALTER TABLE usuarios
ALTER COLUMN nombres DROP NOT NULL
;
¿Es suficiente con el uso de "DEFAULT"?
¿Qué sucede si omitimos la restricción NOT NULL y simplemente establecemos un valor predeterminado?
Probemos creando una nueva columna a la que llamaremos «primer_ingreso», y veamos como queda nuestra tabla
ALTER TABLE usuarios
ADD COLUMN primer_ingreso DATE DEFAULT CURRENT_DATE;

Como podemos observar en el ejemplo, la columna primer_ingreso fue rellenada con la fecha de hoy en todas las filas de la tabla.
Si intentamos agregar una nueva fila sin especificar un valor para primer_ingreso, se le asignará automáticamente el día de hoy.
INSERT INTO usuarios (nombreusuario) VALUES ('piguave01');

Como se demuestra, la nueva fila se inserta correctamente con un valor no nulo en la columna primer_ingreso.
Entonces, ¿es realmente necesario indicar la restricción NOT NULL?
La respuesta es SÍ, ya que se podrían insertar valores nulos especificándolos explícitamente en la instrucción INSERT como se demuestra a continuación.
INSERT INTO usuarios (nombreusuario, primer_ingreso)
VALUES ('piguave02',NULL);
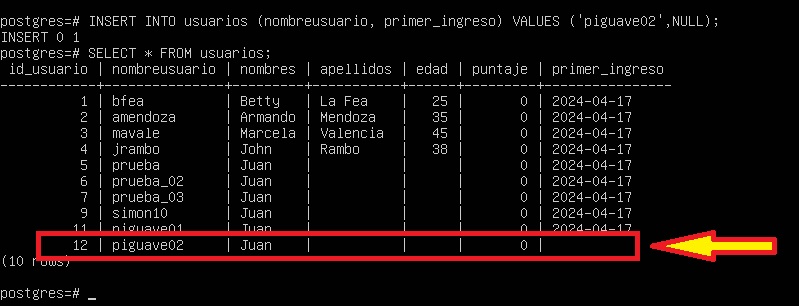
Como se observa en la captura de pantalla anterior, se logró ingresar una nueva fila con un valor NULL para la columna primer_ingreso.
Manejo de NULLs - Consultando valores NULLs
En la sección anterior, exploramos cómo evitar almacenar valores nulos en nuestros sistemas.
Pero, ¿qué sucede si necesitamos manejar los valores nulos existentes en una columna?
En este caso, podemos emplear algunas funciones SQL para detectar esos valores y modificarlos según sea necesario.
Detectar valores nulos con la clausula IS NULL (isnull)
La cláusula IS NULL (que también se puede escribir como ISNULL) nos permite manipular las filas que puedan contener valores nulos.
Por ejemplo:
SELECT * FROM usuarios WHERE apellidos ISNULL;
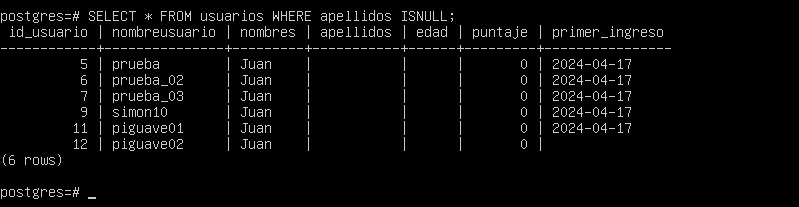
Como se observa, se ha mostrado la lista de filas que contienen valores nulos en la columna apellidos. Una lista con valores opuestos se podría recuperar aplicando la cláusula IS NOT NULL:
SELECT * FROM usuarios WHERE apellidos IS NOT NULL;
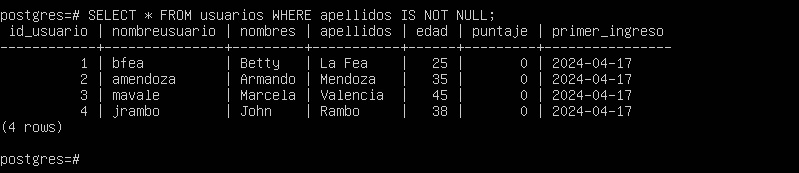
¿Qué sucede si intentamos usar la comparación igual (=)?
SELECT * FROM usuarios WHERE apellidos = NULL;

La consulta anterior no devuelve ninguna fila porque el valor NULL indica que no hay ningún valor y no es igual a ningún otro valor (NULL=NULL es Falso).
Además, si aplicamos el operador de desigualdad (<>) con NULL, también obtenemos NINGUNA fila, ya que el valor NULL indica que no hay ningún valor y, por lo tanto, no es ni igual ni diferente a otros valores.
SELECT * FROM usuarios WHERE apellidos <> NULL;


Asignar un valor predeterminado a NULL utilizando la función COALESCE
En el ejemplo anterior, aprendimos cómo detectar valores nulos.
¿Qué sucede si necesitamos incluirlos en una instrucción SELECT junto con otros valores?
Podemos agregar una condición OR de la siguiente manera:
SELECT * FROM usuarios
WHERE apellidos = 'Valencia' OR apellidos IS NULL ;
También podemos aplicar una transformación para reemplazar los valores nulos con un valor con el que podamos comparar.
SELECT * FROM usuarios
COALESCE(apellidos,'Piguave') in ('Piguave', 'Valencia');
Los dos ejemplos anteriores dan el mismo resultado.
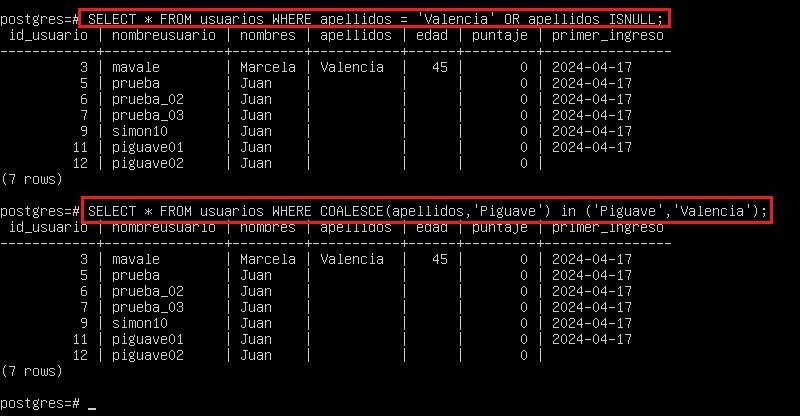
Al optar por la segunda alternativa, es crucial verificar que ‘Piguave’ (la etiqueta asignada a los valores nulos) no esté presente en la columna, o bien, que sea un valor que deseamos incorporar en nuestra selección.
Operaciones matemáticas con NULLs
Un caso similar se presenta cuando debemos realizar cálculos sobre una columna que admite valores nulos.
Por ejemplo, consideremos la columna edad: ¿qué ocurre si deseamos calcular la edad promedio?
Examinemos los datos:
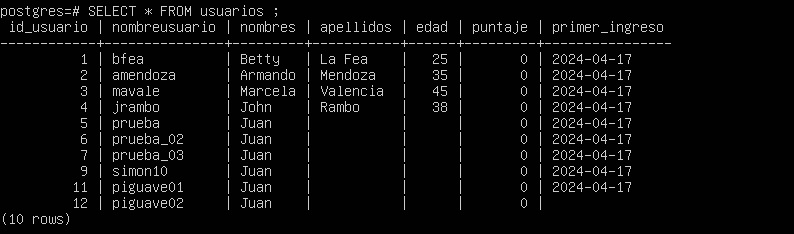
Podemos realizar el calculo de la edad promedio con el siguiente comando:
SELECT AVG(edad) FROM usuarios ;

Esto da como resultado 35.75, que es el promedio de las 4 edades NO NULAS.
Del mismo modo, si consideramos la columna primer_ingreso con el comando:
SELECT COUNT(primer_ingreso) FROM usuarios ;

El resultado es 9, representando una fila por cada usuario con un valor para primer_ingreso distinto de nulo.
¿Qué ocurre si intentamos calcular el puntaje promedio? Para ello, primero actualicemos la tabla asignando a ‘simon10’ un puntaje de 45 puntos.
UPDATE usuarios SET puntaje = 45 WHERE nombreusuario = 'simon10' ;
Procedemos a calcular el puntaje promedio.
SELECT AVG(puntaje) FROM usuarios ;

El resultado es 4.5, que representa el promedio matemático entre los 45 puntos de ‘simon10’ y los ceros del resto, dado que previamente establecimos cero como valor predeterminado.
¿Es esto correcto? ¡Depende! Si nuestra intención era calcular el promedio de puntos únicamente de usuarios activos, este cálculo podría resultar engañoso.
Joins con columnas NULL
Considerando lo que aprendimos previamente sobre la distinción de NULL con respecto a otros valores, es crucial prestar mayor atención al tratar con columnas nulas al momento de realizar JOINS.
Crearemos otra tabla llamada «reuniones» e insertaremos algunos datos.
Por una razón académica en este caso, el diseño de esta tabla nos obligará a realizar una unión (JOIN) con la tabla «usuarios» en la columna«apellidos», la cual acepta valores NULL.
CREATE TABLE reuniones (id_reunion SERIAL, apellidos TEXT, horario TIMESTAMP);
INSERT INTO reuniones (apellidos, horario) VALUES
('Valencia', CURRENT_TIMESTAMP - INTERVAL '1 day'),
('Mendoza', CURRENT_TIMESTAMP - INTERVAL '1 day'*2),
('Rambo', CURRENT_TIMESTAMP - INTERVAL '1 day'*2),
('Rambo', CURRENT_TIMESTAMP),
(NULL, CURRENT_TIMESTAMP),
(NULL, CURRENT_TIMESTAMP - INTERVAL '1 day'*2),
(NULL, CURRENT_TIMESTAMP - INTERVAL '1 day'*2),
(NULL, CURRENT_TIMESTAMP - INTERVAL '1 day'*1),
(NULL, CURRENT_TIMESTAMP);

Si deseamos contar los usuarios que tienen una reunión en cada día, podríamos escribir la consulta siguiente:
SELECT EXTRACT(DAY FROM horario), COUNT(distinct nombreusuario)
FROM reuniones
JOIN usuarios ON reuniones.apellidos=usuarios.apellidos
GROUP BY EXTRACT(DAY FROM horario);
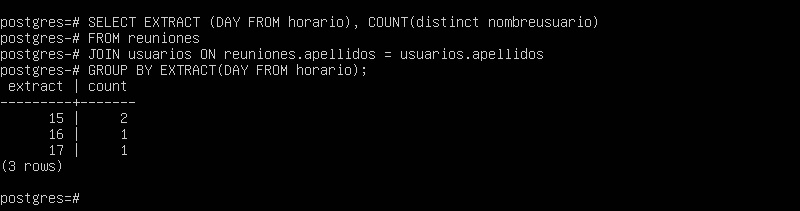
No obstante, el resultado solo muestra 4 reuniones.
¿Por qué ocurre esto? Una vez más, se debe a los valores NULL en la condición del JOIN.
Este problema de baja calidad de datos en ambas partes del JOIN nos impide obtener un número útil.
¿Cómo podríamos solucionarlo? La solución radica en modificar la estructura de la tabla reuniones para utilizar nombreusuario en lugar de los apellidos, además de definir una clave foránea (FOREIGN KEY) adecuada hacia la tabla de usuarios.
Si buscamos una solución simple, podríamos aplicar COALESCE en ambos lados de la unión:
SELECT EXTRACT(DAY FROM horario), COUNT(distinct nombreusuario)
FROM reuniones
JOIN usuarios ON COALESCE(reuniones.apellidos, 'SinApellido') = COALESCE(usuarios.apellidos, 'SinApellido')
GROUP BY EXTRACT(DAY FROM horario);
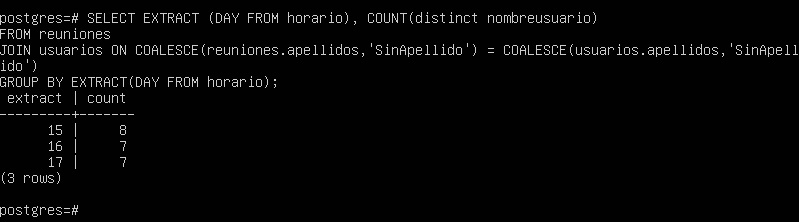
El resultado muestra un incremento en el recuento de reuniones.
Sin embargo, esta aún no es la respuesta correcta, ya que observamos que se están agregando 18 reuniones, mientras que originalmente solo se mostró 4 reuniones en la tabla de reuniones.
¿Por qué ocurre esto? Se debe a que ahora hemos convertido todos los valores NULL en «SinApellido» en ambos lados de la unión (JOIN).
Dado que teníamos 5 reuniones sin apellido y 6 usuarios sin apellido, estamos generando una unión cartesiana de todos los apellidos vacíos con las reuniones vacías.
Habíamos identificado los siguientes usuarios sin apellidos:
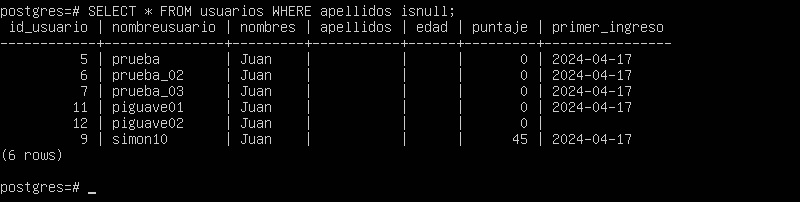
Además las siguientes reuniones sin apellidos:
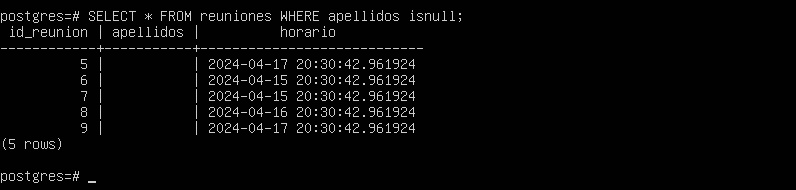
Cada reunión se asoció con cada usuario, lo que generó un exceso de reuniones.
Una solución más adecuada podría ser atribuir todas las reuniones con valor NULL a un único usuario ficticio denominado NoUsuario.
SELECT EXTRACT(DAY FROM horario), COUNT(distinct COALESCE(nombreusuario,'NoUsuario'))
FROM reuniones
LEFT OUTER JOIN usuarios ON reuniones.apellidos = usuarios.apellidos
GROUP BY EXTRACT(DAY FROM horario);
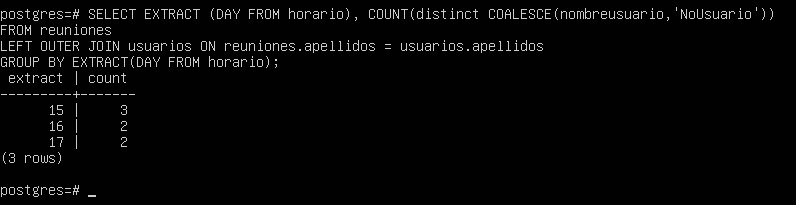
Sin embargo, intentar resolver problemas de calidad de datos durante la consulta rara vez es una estrategia eficaz.
Conclusión
La gestión de valores nulos en las bases de datos es crucial para mantener la integridad y la precisión de los datos.
Hemos explorado cómo los valores nulos pueden afectar las operaciones de consulta y cómo enfrentar estas eventualidades mediante estrategias como el uso de COALESCE, el diseño adecuado de tablas y restricciones.
Es importante reconocer que resolver problemas de calidad de datos en el momento de la consulta puede ser peligroso, y es preferible implementar soluciones estructurales desde el diseño inicial de la base de datos.
Al hacerlo, podemos garantizar la fiabilidad y consistencia de los datos a lo largo del tiempo.











