


El término SQL es el acrónimo de Lenguaje de Consulta Estructurada (Structured Query Language).
Se trata de una forma muy extendida de comunicarse con servidores de bases de datos, ya que es compatible con prácticamente todos los sistemas de bases de datos existentes.
En este artículo, nos adentraremos en el mundo de los sistemas de bases de datos relacionales y aprenderás cómo utilizar los comandos SQL más fundamentales.
INDICE
Comandos Básicos de SQL
Para todos los ejemplos e ilustraciones, estoy utilizando PostgreSQL 15 con un servidor Ubuntu versión 22.04.2 (Jammy Jellyfish).
El objetivo es crear una tabla que contenga los datos de esta forma:
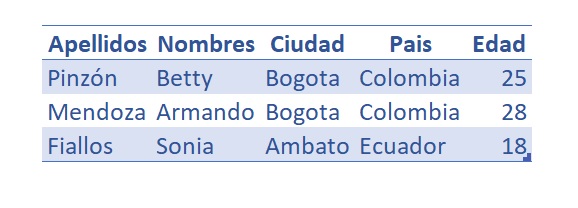
Creación de Tablas - CREATE TABLE
Creemos nuestra propia tabla llamada «amigos», y lo haremos mediante el siguiente comando:
CREATE TABLE amigos
(
nombres char(20),
apellidos char(20),
ciudad char(20),
pais char(20),
edad integer
);

No es necesario que escribas el comando exactamente como en los ejemplos de mas arriba.
Puedes usar minúsculas o escribirlo en una sola línea larga, y funcionará igualmente.
Analicemos la sentencia desde arriba hacia abajo.
Las palabras «CREATE TABLE» tienen un significado especial para el servidor de bases de datos, ya que indican que la siguiente solicitud del usuario es crear una tabla.
En la mayoría de las solicitudes de SQL, estas primeras palabras permiten identificar rápidamente la intención del usuario.
El resto de la solicitud sigue un formato específico entendido por el servidor de bases de datos.
Aunque el uso de mayúsculas y espacios es opcional, es importante seguir exactamente el formato de la consulta.
De lo contrario, el servidor de bases de datos emitirá un mensaje de error.
Explicación del comando
El comando «CREATE TABLE» sigue un formato específico que consta de varias partes: en primer lugar, las palabras «CREATE TABLE«; a continuación, el nombre de la tabla que se va a crear; luego, un paréntesis de apertura para definir las columnas de la tabla, seguido de una lista de nombres de columnas junto con sus tipos de datos; finalmente, un paréntesis de cierre para indicar el final de la declaración.
En ejemplo mostrado, se pueden observar cinco líneas dentro de los paréntesis. Cada línea representa una columna de la tabla que estamos creando.
Por ejemplo, la primera línea «nombres CHAR(20)» define la columna llamada «nombres» con un tipo de dato «CHAR» que puede contener un máximo de 20 caracteres.
De manera similar, la segunda línea define la columna «apellidos» que admite hasta 20 caracteres.
Las columnas de tipo «CHAR()» se utilizan para almacenar caracteres de longitud especificada.
Cuando los usuarios proporcionan cadenas de caracteres que no llenan toda la longitud del campo, se rellenan con espacios en blanco en el extremo derecho.
Las columnas «ciudad» y «pais» siguen un patrón similar, siendo también de tipo CHAR().
Sin embargo, la última columna, «edad», es diferente, ya que es de tipo INTEGER, destinada a almacenar números enteros en lugar de caracteres.
Por lo tanto, aunque la tabla pueda contener miles de registros de amigos, en la columna «edad» solo aparecerán números enteros, sin nombres o caracteres.
Esta estructura coherente en el diseño de la tabla contribuye a la rapidez y confiabilidad de las bases de datos, asegurando que los datos se almacenen de manera adecuada y consistente en cada columna.
Tipos de datos admitidos en PostgreSQL
POSTGRESQL admite una amplia variedad de tipos de columnas, más allá de CHAR() e INTEGER.
Sin embargo, en este artículo nos centraremos únicamente en estos dos tipos.
Ahora, te invito a que crees algunas tablas por ti mismo. Asegúrate de utilizar solo letras para los nombres de tus tablas y columnas. Evita el uso de números, puntuación o espacios en este momento.
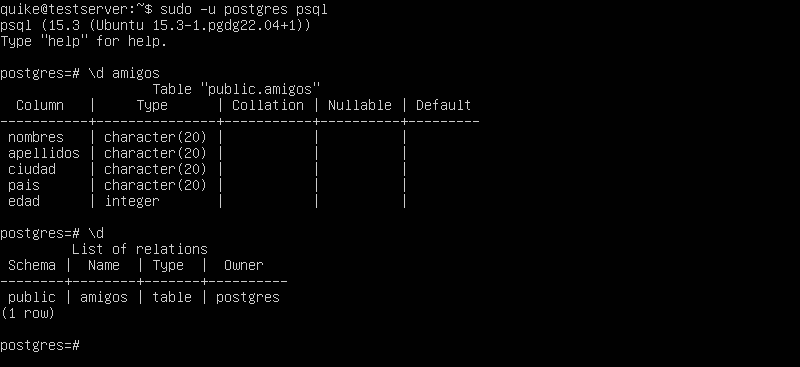
El comando \d te permite obtener información sobre una tabla específica o listar todos los nombres de tablas en la base de datos actual.
Si deseas conocer los detalles de una tabla en particular, simplemente escribe \d seguido del nombre de la tabla.
Por ejemplo, para ver los nombres y tipos de columna de la nueva tabla «amigos» en psql, escribe:
\d amigos
Si utilizas el comando \d sin especificar un nombre de tabla, se mostrará una lista con todos los nombres de tablas presentes en la base de datos.
Agregando datos con INSERT
Sigamos avanzando hacia el objetivo de crear una tabla idéntica a la tabla de amigos mostrada al inicio del artículo.
Hasta el momento, hemos creado la tabla, pero aún no contiene ningún amigo.
Para agregar filas a la tabla, utilizaremos la instrucción INSERT.
Al igual que CREATE TABLE, INSERT también tiene un formato específico que debemos seguir.
INSERT INTO amigos VALUES
(
'Pinzón','Betty','Bogota','Colombia',25
);

Es importante utilizar comillas simples alrededor de las cadenas de caracteres.Las comillas dobles no serán reconocidas correctamente.
El espaciado y las mayúsculas son opcionales, excepto dentro de las comillas simples.
Dentro de ellas, el texto se toma literalmente, por lo que cualquier mayúscula se almacenará en la base de datos tal como lo especifiques.
Es recomendable tener cuidado con el uso excesivo de comillas para evitar que los comandos de barra invertida (\) dejen de funcionar adecuadamente y puedan surgir problemas en la indicación, como «pruebas’>«, con la comilla simple antes del símbolo mayor que.
Para salir de este modo, simplemente escribe otra comilla simple.
Si surge algún problema con el búfer de consulta, puedes utilizar \r para limpiarlo y comenzar de nuevo.
Es importante notar que el número 25 no requiere comillas. Esto se debe a que la columna es de tipo numérico, no de caracteres.
Al realizar operaciones de INSERT, es fundamental asegurarse de que cada dato coincida correctamente con la columna receptora. De esta manera, se garantiza la integridad y la coherencia de la información en la tabla.
Para completar el ingreso de los dos amigos restantes ejecutamos:
INSERT INTO amigos VALUES
(
'Mendoza','Armando','Bogota','Colombia',28
);
INSERT INTO amigos VALUES
(
'Fiallos','Sonia','Ambato','Ecuador',18
);

Visualización de datos con SELECT
Acabas de aprender cómo almacenar datos en la base de datos.
Ahora, nos enfocaremos en recuperar esos datos. Solo necesitamos un comando para obtener información de la base de datos: SELECT.
Con el comando SELECT, podemos recuperar y visualizar los datos almacenados en las tablas de manera eficiente y precisa.
Entonces utilizaremos el comando SELECT para mostrar las filas en la tabla «amigos».
SELECT * FROM amigos;

Como se muestra en la captura de pantalla toda la consulta aparece en una sola línea.
Sin embargo, a medida que las consultas se vuelven más largas, dividirlas en múltiples líneas ayuda a que las cosas sean más claras y legibles.
Explicación del comando
Analicemos este ejemplo en detalle.
En primer lugar, encontramos la palabra SELECT, seguida de un asterisco (*), luego la palabra FROM, seguida del nombre de nuestra tabla «amigos» y, finalmente, un punto y coma para ejecutar la consulta.
El comando SELECT inicia nuestra consulta, indicando al servidor de la base de datos lo que queremos obtener.
El asterisco (*) le dice al servidor que deseamos todas las columnas de la tabla.
La cláusula FROM seguida de «amigos» indica qué tabla queremos consultar.
Por lo tanto, hemos especificado que deseamos recuperar todas (*) las columnas de nuestra tabla «amigos».
En efecto, esto muestra los mismos datos que se presentan en la tabla amigos ilustrada al inicio de este artículo.
Variantes del comando SELECT
SELECT ofrece una variedad de opciones y exploraremos algunas de ellas ahora.
Supongamos que deseas recuperar solo una columna específica de la tabla «amigos».
Es probable que ya sospeches que debes reemplazar el asterisco (*) en la consulta.
Si lo cambias por el nombre de una columna, obtendrás solo esa columna.
Por ejemplo, intenta lo siguiente:
SELECT ciudad FROM amigos;

Puedes elegir cualquier columna que desees. Incluso tienes la posibilidad de seleccionar múltiples columnas, simplemente separando los nombres con comas.
Por ejemplo, para obtener solo los nombres y apellidos, utiliza:
SELECT nombres, apellidos FROM amigos;

Experimenta con otras consultas SELECT hasta que te sientas cómodo con su uso.
Si especificas un nombre que no corresponde a una columna válida, recibirás un mensaje de error como «ERROR: atributo ‘mi_nombre_de_columna’ no encontrado«.
Asimismo, si intentas seleccionar de una tabla que no existe, recibirás un mensaje de error como «ERROR: la relación ‘mi_nombre_de_tabla’ no existe«.
POSTGRESQL emplea los términos formales de base de datos relacionales «relación» y «atributo» en estos mensajes de error.
Seleccionando Filas Específicas con WHERE
La cláusula WHERE nos permite seleccionar filas específicas de una tabla que cumplan ciertas condiciones.
Es una herramienta poderosa para filtrar los datos que necesitamos de una tabla más grande.
Por ejemplo, si queremos obtener solo los registros de amigos que tienen una edad mayor a 20 años, podemos utilizar la cláusula WHERE de la siguiente manera:
SELECT * FROM amigos WHERE edad > 20;

Esto nos devolverá todas las filas de la tabla «amigos» donde la edad es mayor a 20.
Podemos utilizar diferentes operadores lógicos como «=», «<«, «>», «>=», «<=», etc., para definir diferentes condiciones y filtrar los resultados de acuerdo a nuestras necesidades.
Puedes combinar las restricciones de columnas y filas en una sola consulta, lo que te permite seleccionar tanto celdas individuales como bloques de celdas.
Esto te brinda una mayor flexibilidad para obtener los datos específicos que necesitas de la tabla.
Hasta ahora, solo hemos realizado comparaciones en la columna de edad, que es de tipo INTEGER.
La parte complicada sobre las otras columnas es que son de tipo CHAR(), por lo que debes colocar los valores de comparación entre comillas simples.
Además, es importante que coincidas exactamente con los valores que deseas comparar.
Esto garantizará que las consultas devuelvan los resultados deseados.
SELECT * FROM amigos WHERE nombres = 'Mendoza';

Sigue probando algunas consultas más hasta que te sientas cómodo con esta operación.
Practicar te ayudará a familiarizarte con el proceso y a mejorar tu habilidad con esta operación.
¡No dudes en experimentar y practicar para ganar confianza en su uso!
Eliminar datos con DELETE
Aprendimos cómo agregar datos a la base de datos; ahora vamos a aprender cómo eliminarlos.
La eliminación es bastante sencilla.
El comando DELETE puede eliminar rápidamente una o todas las filas de una tabla.
Por ejemplo, el comando DELETE FROM amigos eliminará todas las filas de la tabla «amigos».
Si deseamos eliminar solo ciertas filas que cumplan con cierta condición, podemos usar la consulta DELETE FROM amigos WHERE edad = 19 para eliminar únicamente aquellas filas que tengan un valor de 19 en la columna de «edad».
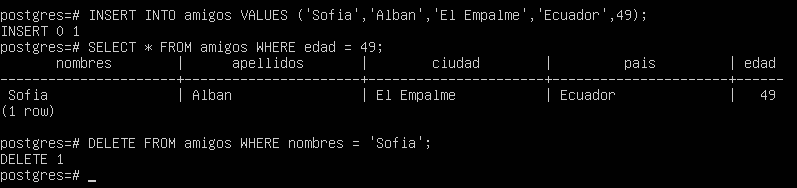
Para practicar, aquí tienes un buen ejercicio: utiliza el comando INSERT para agregar una fila a la tabla «amigos», luego emplea SELECT para verificar que la fila se ha agregado correctamente y, finalmente, utiliza DELETE para eliminar la fila que has insertado.
Este ejercicio combina las ideas que has aprendido en las secciones anteriores y te permitirá reforzar tus conocimientos. ¡Anímate a realizarlo!
INSERT INTO amigos VALUES
(
'Sofia','Alban','El Empalme','Ecuador',49
);
SELECT * FROM amigos WHERE edad = 49;
DELETE FROM amigos WHERE nombres = 'Sofia';
Modificar datos con UPDATE
¿Cómo podemos modificar los datos existentes en la base de datos?
Podríamos utilizar DELETE para eliminar una fila y luego INSERT para insertar una nueva fila con los datos actualizados, pero esto resultaría bastante ineficiente.
Afortunadamente, el comando UPDATE nos permite actualizar los datos ya presentes en la base de datos de manera más eficiente.
Este comando sigue un formato similar a los comandos que hemos visto anteriormente.
Tomando como ejemplo nuestra tabla «amigos», supongamos que Sonia Fiallos ha cumplido años y deseamos actualizar su edad en la tabla.
A continuación un ejemplo del comando UPDATE, donde se menciona el nombre de la tabla «amigos», seguido de SET, el nombre de la columna, el signo igual (=) y el nuevo valor para la edad de Sonia Fiallos.
La cláusula WHERE controla qué filas se verán afectadas por esta actualización, al igual que en una operación DELETE.
Sin una cláusula WHERE, todas las filas de la tabla se actualizarán.
UPDATE amigos SET edad = 19 WHERE nombres = 'Fiallos' AND apellidos = 'Sonia';

Es importante destacar que, tras la actualización, la fila de Sonia Fiallos se ha movido al final de la lista en la tabla.
En la siguiente sección, explicaremos cómo controlar el orden de visualización de los datos.
El comando UPDATE es una herramienta valiosa para modificar datos existentes de manera eficiente y precisa en la base de datos.
Ordenando datos con ORDER BY
En una consulta SELECT, las filas se muestran en un orden indeterminado por defecto.
Sin embargo, si deseas asegurarte de que las filas se devuelvan en un orden específico, puedes agregar la cláusula ORDER BY al final de tu consulta SELECT.
SELECT * FROM amigos ORDER BY edad;

En la captura de pantalla anterior, podemos observar el uso de ORDER BY, que nos permite ordenar los resultados en un orden específico.
Si deseamos invertir el orden de los resultados, podemos agregar DESC, como se muestra a continuación.
SELECT * FROM amigos ORDER BY edad DESC;

Por otro lado, si nuestra consulta incluye una cláusula WHERE, la cláusula ORDER BY aparecerá después de la cláusula WHERE, como se ilustra a continuación.
SELECT * FROM amigos WHERE edad > 20 ORDER BY edad;

De esta manera, podemos controlar tanto la selección de filas mediante la cláusula WHERE como el orden en que se presentarán los resultados mediante ORDER BY.
Es posible realizar una clasificación más compleja mediante el uso de múltiples columnas en la cláusula ORDER BY.
Para ello, simplemente se especifican varios nombres o etiquetas de columnas separados por comas.
El comando de clasificación se aplicará primero según la primera columna especificada, y en caso de empates en esa columna, se utilizará la segunda columna para realizar una clasificación adicional.
Este enfoque es útil cuando se requiere una clasificación más precisa y detallada de los datos.
Sin embargo, en el ejemplo de la tabla «amigos», este enfoque de ordenación no sería de utilidad práctica, ya que todos los valores de las columnas son únicos y no habría empates en la clasificación.
Eliminar Tablas
Para finalizar este articulo, es importante mencionar cómo eliminar tablas de la base de datos.
Esta tarea se realiza mediante el comando DROP TABLE.
Por ejemplo, si ejecutas el comando DROP TABLE amigos, se eliminará por completo la tabla «amigos», incluyendo tanto su estructura como los datos almacenados en ella.
Sin embargo, ten en cuenta que en el próximo articulo utilizaremos la tabla «amigos», por lo que no debes eliminarla en este momento.
Si deseas eliminar únicamente los datos contenidos en la tabla sin borrar su estructura, puedes utilizar el comando DELETE.












